
Contar Duplicados en MySQL
![]()
Supongamos que tenemos la siguiente estructura en una tabla sql
id name 1 AAA 2 BBB 3 BBB 4 BBB 5 AAA 6 CCC select count(name) c from tbl group by name having c >1
al ejecutar esta query obtendremos el siguiente resultado:
AAA(2) duplicate BBB(3) duplicate CCC(1) not duplicate
Los nombres que son duplicados son AAA y BBB. Supongamos que el resultado inal que necesitamos es el total de duplicados en esa tabla en este caso seria 2 (AAA y BBB) para lograr este resultado debemos ejecutra la siguiente query
SELECT count(*) AS duplicate_count FROM ( SELECT name FROM tbl GROUP BY name HAVING COUNT(name) > 1 ) AS t
Esta query lo que hace es hacer un count de los resultados de la query interna.
SQLSTATE[HY000] [2003] Can’t connect to MySQL server on ‘xxx.xxx.xxx.xxx’ (13)
![]()
Una de las cosas que nos puede causar un dolor de cabeza, y quizas no es tan facil de encontrar en google es cuando PHP rehusa conectarse a un servidor remoto MySQL mostrando el error:
SQLSTATE[HY000][2003]Can't connect to MySQL server on 'xxx.xxxx.xxx.xxx' (13)
Luego de hacer una prueba de conexión con el shell local y ver que se realiza la conexión correctamente, el primer pensamiento que se me ocurre es que hay algo mal en la última actualización del framework que estoy utilizando, pero después de un tiempo me di cuenta que la respuesta es muy simple.
SELinux está bloqueando las conexiones remotas desde scripts PHP ejecutados por un servidor web Apache. El código de error (13) al final del mensaje de error significa "permiso denegado" por lo cual es la indicación de que existe un bloqueo.
Como les había comentado la solución es sencilla: deben loguearse al servidor remoto como root y ejecutar el siguiente comando:
setsebool -P httpd_can_network_connect=1
y el problema estará solucionado.
Por supuesto, piense dos veces antes de ejecutar este comando porque harás tu servidor web un poco menos seguro, así que no hagas eso a menos que estés seguro de que lo necesite.
phpMyAdmin: Buscar y reemplazar
![]()
Aqui tienen un gran tip que les puede ahorrar muchas horas de trabajo.
Si alguna vez usted se ha equivocado con caracteres en su base de datos - codificacion de caracteres incorrecta - o simplemente quiere eliminar una cadena de texto en un campo especifico de una tabla en phpMyadmin, usted puede abrir el "SQL Dialog" y usar el siguiente codigo para realizar este reemplazo (recuerde cambiar tablename y tablefield por sus respectivos valores).
UPDATE tablename SET tablefield = replace(tablefield, "findstring", "replacestring");
Usted tambien puede hacer uso del la clausula WHERE si lo desea.
Probado en MySQL5, PHP5 y phpMyAdmin 2.11.4.
Update: Necesitara poner "replace" en mayuscula cerrada ("REPLACE") en las versiones mas recientes de phpMyAdmin.
20 Consejos para Mejorar tu MySQL que quizás no conocías
Las operaciones sobre bases de datos suelen ser los principales cuellos de botella en las aplicaciones web. Por tanto es tarea de los programadores estructurar apropiadamente, escribir peticiones apropiadas, y programar mejor código. A continuación mostramos algunas técnicas de optimización MySQL.
1. Optimiza tus peticiones para la caché.
La mayoría de servidores MySQL tienen habilitado el sistema de caché. Es uno de los métodos más efectivos para mejorar el rendimiento, que vienen de la mano del motor de base de datos. Cuando la misma petición se ejecuta varias veces, el resultado se obtiene de la caché, que resulta mucho más rápida.
El problema es que, es tan sencillo y transparente para el programador, que la mayoría de nosotros tendemos a ignorarlo. Algunas cosas que hacemos de hecho pueden evitar que la caché haga su trabajo.
//La cache NO funciona $r = mysql_query("SELECT nombre FROM usuarios WHERE registro >= CURDATE()"); // La caché sí funciona $hoy = date("Y-m-d"); $r = mysql_query("SELECT nombre FROM usuarios WHERE registro >= ‘$hoy’"); la razón por la que no funciona en el primer caso es por el uso de CURDATE(). Puede aplicarse a todas las funciones no deterministas, como NOW() y RAND(). Dado que el resultado retornado por la función puede cambiar, MySQL decide deshabitar la caché en esa consulta.
2. Usa EXPLAIN en tus consultas SELECT
Utilizar la palabra clave EXPLAIN te dará muchos detalles internos de lo que hace MySQL para ejecutar tu consulta. Esto te puede ayudar a detectar los cuellos de botella y otros problemas con tu query o la estructura de la tabla.
El resultado de una query EXPLAIN te mostrará los índices que se están utilizando, cómo se está explorando la tabla, cómo se está ordenando, etc…
Coge una consulta SELECT (preferiblemente una compleja, con uniones), y añade la palabra EXPLAIN al principio del todo. Puedes utilizar por ejemplo PhpMyAdmin para esto. Te devolverá los resultados en una sencilla tabla. Por ejemplo, pongamos que me he olvidado de poner un índice a una columna, con la que estoy ejecutando

Después de añadir el índice al campo group_id:
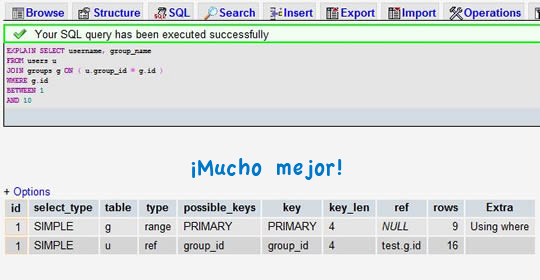
Ahora en lugar de escanear 7883 filas, sólo escaneará 9 y 16 filas de las dos tablas.
3. Usa LIMIT 1 Cuando sólo quieras una única fila.
A veces, cuando estás realizando consultas a tus tablas, ya sabes que sólo necesitas una única fila. En estos casos debes solicitar a la base de datos un único resultado, o de lo contrario comprobará todos y cada uno de las coincidencias de la cláusula WHERE.
En estos casos, añadir LIMIT 1 a tu query puede mejorar significativamente la velocidad. De esta forma la base de datos dejará de escanear resultados en el momento que encuentre uno, en lugar de recorrer toda la tabla o un índice.
// Tengo usuarios de Valencia? // lo que NO hay que hacer: $r = mysql_query("SELECT * FROM user WHERE ciudad = ‘Valencia’"); if (mysql_num_rows($r) > 0) { // … } // mucho mejor: $r = mysql_query("SELECT 1 FROM user WHERE ciudad = ‘Valencia’ LIMIT 1"); if (mysql_num_rows($r) > 0) { // … } 4. Indexa los campos de Búsqueda
Los índices no son sólo para las claves primarias o las claves únicas. Si en tu tabla hay columnas sobre las que vas a realizar búsquedas, deberías indexarlas casi siempre.

Como puedes ver, esta regla se aplica también a las búsquedas parciales como “apellido LIKE ‘a%’”. Cuando se busca desde el comienzo de la cadena, MySQL es capaz de utilizar el índice de esta columna.
Deberías también comprender en qué tipos de búsqueda no pueden utilizarse índices normales. Por ejemplo, cuando buscas una palabra dentro de un texto (p.e. “WHERE contenido LIKE ‘%manzana%’”), no observarás ningún beneficio con un índice normal. En este caso sería mejor utilizar una búsqueda FULLTEXT o construir tu propia solución de indexación.
5. Indexa, y utiliza el mismo tipo de columna para los Join
Si tu aplicación contiene muchas sentencias JOIN debes asegurarte de que las columnas que unes están indexadas en ambas tablas. Esto afecta en cómo MySQL optimiza internamente las operaciones JOIN.
Además, las columnas que vas a unir deben ser del mismo tipo. Por ejemplo, si estás uniendo una columna de tipo DECIMAL con una columna de tipo INT de otra tabla, MySQL no será capaz de usar al menos uno de los dos índices. Incluso la codificación de caracteres necesita ser del mismo tipo para las columnas de tipo String.
// buscando compañias en mi ciudad $r = mysql_query("SELECT nombre_companyia FROM usuarios LEFT JOIN companyias ON (usuarios.ciudad = companyias.ciudad) WHERE usuarios.id = $user_id"); // ambas columnas ciudad deben estar indexadas // y ambas deberían ser del mismo tipo y codificación de caracteres // o MySQL tendrá que hacer un escaneo total de las tablas 6. No uses ORDER BY RAND()
Éste es uno de esos truquillos que suenan muy bien a primera vista, y donde muchos programadores novatos suelen caer. Puede que no hayas caído en la cuenta del increíble cuello de botella que se puede provocar si utilizas esta técnica en tus peticiones.
Si en verdad necesitas tablas aleatorias para tu resultado, hay formas mucho mejores de hacerlo. Está claro que ocuparán más código, pero estarás previniendo un posible embotellamiento que aumenta exponencialmente a medida que tu contenido crece. El problema es que MySQL tendrá que ejecutar RAND() (que requiere de potencia de procesado) para cada una de las filas antes de ordenarlas y devolver una simple fila.
// la forma de NO hacerlo: $r = mysql_query("SELECT nombreusuario FROM usuarios ORDER BY RAND() LIMIT 1"); // mucho mejor: $r = mysql_query("SELECT count(*) FROM usuarios"); $d = mysql_fetch_row($r); $rand = mt_rand(0,$d[0] – 1); $r = mysql_query("SELECT nombreusuario FROM usuarios LIMIT $rand, 1"); De forma que seleccionas un número aleatorio inferior a la cantidad de resultados y lo usas como el desplazamiento en la cláusula LIMIT.
7. Evita SELECT *
Cuanta más información se lee de las tablas, más lenta se ejecutará la petición SQL. Aumenta el tiempo que toma para las operaciones en disco. Además cuando el servidor de bases de datos está separado del servidor web, tendrás mayores retrasos de red debido a que la información tiene que ser transferida entre ambos servidores.
Es un buen hábito especificar siempre las columnas que necesitas cuando estás haciendo un SELECT.
// preferible no hacer: $r = mysql_query("SELECT * FROM usuarios WHERE id_usuario = 1"); $d = mysql_fetch_assoc($r); echo "Bienvenido {$d['nombreusuario']}"; // mejor: $r = mysql_query("SELECT nombreusuario FROM usuarios WHERE id_usuario = 1"); $d = mysql_fetch_assoc($r); echo "Bienvenido {$d['nombreusuario']}"; // las diferencias son mucho más significativas cuanta más información haya 8. Ten casi siempre un campo identificativo
Ten en cada tabla una columna id con las propiedades PRIMARY KEY, AUTO_INCREMENT y alguna de las variantes de INT. Además es preferible que sea UNSIGNED (sin signo) ya que el valor nunca podrá ser negativo.
Incluso si tienes una tabla de usuarios cuyos nombres de usuario sean únicos, no los uses como clave primaria. Los campos VARCHAR como clave primaria son muy lentos. Y tendrás una mejor estructura en tu código si referencias a todos tus usuarios por sus ids internamente.
También hay una serie de operaciones internas que realiza el motor de MySQL por sí mismo, que usa la clave primaria, lo cual se hace incluso más importante cuanto más compleja sea la base de datos (clusters, particionados, etc…).
Una posible excepción a la regla son las “tablas de asociación”, utilizadas en las relaciones “muchos a muchos” entre dos tablas. Por ejemplo, una tabla “etiquetas_articulos” que contiene dos columnas: id_articulo, id_etiqueta, que es utilizada para las relaciones entre las tablas “articulos” y “etiquetas”. Estas tablas pueden tener una clave PRIMARY que contenga ambos campos.
9. Usa ENUM antes que VARCHAR
Las columnas de tipo ENUM son muy rápidas y compactas. Internamente se almacenan como TINYINT, aunque pueden contener y representar valores de cadenas. Esto las hace un perfecto candidato para algunos campos.
Si tienes un campo que contendrá sólo unos pocos valores distintos, utiliza ENUM en lugar de VARCHAR. Por ejemplo, podría ser una columna llamada “estado”, y sólo unos pocos valores como “activo”, “inactivo”, “pendiente”, “caducado”, etc…
De hecho hay una forma de obtener sugerencias del propio MySQL para reestructurar nuestra tabla. Cuando tienes un campo VARCHAR te puede sugerir que cambies ésa columna al tipo ENUM. Esto se hace utilizando la llamada a PROCEDURE ANALYSE(). Lo cual nos lleva a:
10. Obtén sugerencias con PROCEDURE ANALYSE()
PROCEDURE ANALYSE() permitirá a MySQL analizar la estructura de las columnas y los datos actuales que contienen para retornar ciertas sugerencias que serán de tu interés. Sólo es útil si hay información en las tablas, porque esto toma gran importancia en la toma de decisiones.
Por ejemplo, si creaste un campo INT para tu clave primaria, pero no tienes muchas filas, podría sugerirte que uses MEDIUMINT en su lugar. O si estas usando un campo VARCHAR, podría sugerirte que lo conviertas en ENUM, si sólo estás escribiendo unos pocos valores.
También puedes ejecutarlo pulsando en “Propose table structure” (proponer estructura de tabla) en la interfaz de PhpMyAdmin, en una de las vistas de tus tablas.

Ten presente que esto son sólo sugerencias. Y si tu tabla va a crecer mucho, podrían no ser buenas sugerencias a seguir. La decisión es tuya en última instancia.
11. Usa NOT NULL si puedes
A no ser que tengas una razón específica para usar el valor NULL, deberías establecer siempre tus columnas como NOT NULL.
En primer lugar, pregúntate a tí mismo si habría alguna diferencia entre tener una cadena vacía y un valor NULL (o para campos INT: 0 contra NULL). Si no hay problema entre los dos valores, no necesitas un campo NULL. (¿Sabías que Oracle considera a NULL y una cadena vacía como lo mismo?)
Las columnas NULL necesitan espacio adicional y pueden añadir complejidad a tus sentencias de comparación. Simplemente evítalas siempre que puedas. En cualquier caso, entiendo que en algunos casos muy específicos haya razón para usar columnas NULL, lo cual no es siempre algo malo.
Extraído de la documentación de MySQL:
"las columnas NULL requieren espacio adicional en la fila a grabar donde los valores son NULL. Para las tablas MyISAM, cada columna NULL toma un bit extra, redondeando hacia arriba al byte más cercano."
12. Declaraciones preparadas
Existen múltiples beneficios al usar declaraciones preparadas, tanto a nivel de productividad como de seguridad.
Las declaraciones preparadas filtran las variables que le pasas por defecto, lo que es perfecto para proteger tu aplicación contra ataques de inyección SQL. Claro que puedes filtrar tus variables manualmente, pero estos métodos son propensos al error humano y al despiste del programador. Este problema no es tan acentuado cuando se utiliza algún tipo de Framework u ORM.
Ya que queríamos centrarnos en la productividad, deberíamos mencionar los beneficios que ofrece este area. Estos beneficios son más significativos cuando la misma consulta va a utilizarse varias veces en tu aplicación. Puedes asignar diferentes valores a una misma declaración, y MySQL sólo tendrá que analizarla una vez.
Además, las últimas versiones de MySQL transmiten declaraciones preparadas de forma binaria nativamente, más eficientes y que ayudan a reducir los retrasos de red.
Hubo un tiempo en que muchos programadores solían evitar las declaraciones preparadas a propósito, por una única razón: no estaban siendo cacheadas por la caché de consultas de MySQL. Pero aproximadamente en la versión 5.1, el cacheo de consultas también ha sido soportado.
Para utilizar declaraciones preparadas en PHP puedes echar un ojo a la extensión mysqli o utilizar una capa de abstracción de base de datos como PDO.
// creamos la declaración preparada if ($stmt = $mysqli->prepare("SELECT nombre FROM usuarios WHERE ciudad=?")) { // pasamos los parámetros $stmt->bind_param("s", $ciudad); // ejecutamos $stmt->execute(); // pasamos la variable de resultado $stmt->bind_result($nombre); // obtenemos el resultado $stmt->fetch(); printf("%s es de %s\n", $nombre, $ciudad); $stmt->close(); } 13. Consultas fuera de buffer
Normalmente cuando estás ejecutando una consulta en un script, éste se esperará a que acabe la ejecución de esta consulta antes de que pueda continuar. Pero puedes cambiar este comportamiento sacando la consulta fuera del búffer.
Puedes echar un ojo a la genial explicación que hacen en la documentación de PHP para la función the mysql_unbuffered_query():
“mysql_unbuffered_query() envía la query SQL a MySQL, sin recuperar ni colocar en búfer las filas de resultado automáticamente, como mysql_query() lo hace. Por una parte, esto ahorra una considerable cantidad de memoria con las consultas SQL que producen conjuntos grandes de resultados y se puede empezar a trabajar con el conjunto de resultado inmediatamente después de que la primera fila ha sido recuperada: no necesita esperar hasta que la consulta SQL completa haya sido ejecutada. Para usar mysql_unbuffered_query() cuando se usan múltiples conexiones con la BD, se necesita indicar el parámetro opcional link_identifier para identificar que conexión se desea utilizar.”
Sin embargo los beneficios de mysql_unbuffered_query() tienen un precio: no poder usar mysql_num_rows() ni mysql_data_seek() en un conjunto de resultados devuelto por mysql_unbuffered_query(). También tendrás que recuperar todas las filas de resultado de una consulta SQL sin búfer antes de poder enviar una nueva consulta SQL a MySQL.
14. Almacena las direcciones IP como UNSIGNED INT
Muchos programadores crearían un campo VARCHAR(15) sin darse cuenta de que pueden almacenar las direcciones IP como números enteros. Cuando usas un INT sólo haces uso de 4 bytes en la memoria, y cuenta además con un tamaño fijo en la tabla.
Pero hay que asegurarse de que la columna sea UNSIGNED INT (entero sin signo) porque las direcciones IP hacen uso de todo el rango de 32 bits sin signo.
En tus consultas puedes utilizar la función INET_ATON() para convertir una dirección IP en entero, e INET_NTOA() para hacer lo contrario. También existen funciones parecidas en PHP llamadas ip2long() y long2ip().
$r = "UPDATE users SET ip = INET_ATON(‘{$_SERVER['REMOTE_ADDR']}’) WHERE user_id = $user_id";15. Las tablas de tamaño fijo (Estáticas) son más rápidas
Cuando cada una de las columnas en una tabla es de tamaña fijo (“fixed-length”), la tabla entera se considera "estática" o de "tamaño fijo". Algunos ejemplos de tipos de columna que NO son de tamaño fijo son: VARCHAR, TEXT, BLOB. Si incluyes sólo uno de estos tipos de columna, la tabla dejará de ser de tamaño fijo y tendrá que ser tratada de forma distinta por el motor de MySQL.
Las tablas de tamaño fijo pueden incrementar la productividad porque para el motor de MySQL es más rápido buscar entre sus registros. Cuando quiere leer una fila en concreto de la tabla, puede calcular rápidamente la posición que ocupa. Si el tamaño de fila no es fijo, cada vez que tiene que buscar, ha de consultar primero el índice de la clave primaria.
También resultan más sencillas de cachear, y de reconstruir después de un accidente. Pero por otra parte también podrían ocupar más espacio. Por ejemplo, si conviertes un campo VARCHAR(20) en CHAR(20), siempre ocupará 20 bytes en la memoria independientemente de lo que contenga.
Usando técnicas de “Particionado Vertical”, puedes separar las columnas de tamaño variable en una tabla aparte. Lo cual nos lleva a:
16. Particionado Vertical
El particionado vertical es el acto de separar la estructura de tu tabla de forma vertical por razones de optimización.
Ejemplo 1: Seguramente tendrás una tabla de usuarios que contiene una dirección postal, la cual no se utiliza muy a menudo. Aquí podrías dividir la tabla y almacenar las direcciones en una tabla separada. De esta forma tu tabla de usuarios principal tendría un tamaño más ajustado. Como sabes, cuanto más pequeñas más rápidas son las tablas.
Ejemplo 2: Tienes un campo de “ultimo_acceso” en tu tabla. Se actualiza cada vez que un usuario accede a tu página. Pero cada acceso hace que la cache de consultas de esa tabla se libere. Lo que puedes hacer es colocar este campo en otra tabla para que las modificaciones en tu tabla de usuarios se mantenga al mínimo.
Pero también tienes que asegurarte de que no necesitas juntar las dos tablas constantemente después del particionado o sufrirás una caída en el rendimiento, justo lo contrario a lo que buscábamos.
17. Divide las consultas DELETE o INSERT grandes
Si necesitas ejecutar una consulta DELETE o INSERT que sea grande en una página web activa, tienes que tener cuidado de no alterar el tráfico web. Cuando una consulta grande como esas se ejecuta, puede bloquear tus tablas y paralizar tu aplicación web momentaneamente.
Apache ejecuta muchos procesos/hilos paralelamente. De ahí que funcione mucho más eficientemente cuando los scripts dejan de ejecutarse tan pronto como es posible, para que los servidores no experimenten muchas conexiones abiertas y procesos de una que consumen recursos, especialmente memoria primaria.
Si en algún momento bloqueas tus tablas en un periodo largo (como 30 segundos o más), en una web con mucho tráfico, causarás un apilamiento de procesos y consultas, que llevará mucho tiempo de concluir o que incluso podría estropear tu servidor web.
Si tienes algún script de mantenimiento que tiene que borrar una gran cantidad de filas, simplemente utiliza la cláusula LIMIT para hacerlo en porciones más pequeñas y así evitar la congestión.
while (1) { mysql_query("DELETE FROM logs WHERE log_date <= ’2009-10-01′ LIMIT 10000"); if (mysql_affected_rows() == 0) { // finalizado el borrado break; } // incluso viene bien parar un poco usleep(50000); } 18. Las columnas pequeñas son más rápidas
En los motores de bases de datos, la memoria en disco probablemente sea el cuello de botella más significativo. En términos de productividad, mantener las cosas reducidas y más compactas suele ayudar a reducir la cantidad de transferencia desde disco.
La documentación de MySQL tiene una lista de Requerimientos de Almacenamiento para todos los tipos de dato.
Si está previsto que una tabla tenga muy pocos registros, no hay razón para usar un INT para la clave primaria, en lugar de un MEDIUMINT, SMALLINT o incluso en algunos casos TINYINT. Y si no necesitas el componente del tiempo, puedes utilizar DATE en lugar de DATETIME.
Simplemente, debes asegurarte de que dejas espacio razonable para poder crecer, o podrías acabar como Slashdot.
19. Escoge el motor de almacenamiento adecuado
Los dos principales motores en MySQL son MyISAM y InnoDB, Cada uno tiene sus pros y sus contras.
MyISAM is adecuado para aplicaciones con mucha lectura, pero no escala cuando hay muchas escrituras. Incluso si estás editando un campo de una fila, la tabla completa se bloquea, y ningún otro proceso puede siquiera leer hasta que la consulta ha finalizado. MyISAM es muy rápido calculando consultas de tipo SELECT COUNT(*).
Inno DB tiende a ser un motor más complicado y puede ser más lento que MyISAM para la mayoría de aplicaciones pequeñas. Pero soporta bloqueo basado en fila, lo cual escala mejor. También soporta algunas características más avanzadas como las transacciones.
20. Usa un Mapeador de objetos relacionales
Al usar un ORM (Object Relational Mapper), puedes conseguir algunas mejoras en la productividad. Cualquier cosa que puede hacer un ORM, puedes programarlo a mano también. Pero podría significar demasiado trabajo extra y requerir de un alto nivel de experiencia.
Los ORM son perfectos para la “carga perezosa”. Significa que se puede obtener valores sólo cuando se necesitan. Pero hay que tener cuidado porque podría acabar creando demasiadas mini peticiones que perjudicarían al rendimiento.
Los ORM también pueden agrupar tus consultas en transacciones, que operan mucho más rápido que enviar consultas individuales a la base de datos.
Actualmente un ORM recomendable para PHP es Doctrine. Puedes leer cómo instalarlo en este artículo (inglés).
21. Ten cuidado con las conexiones persistentes
El objetivo de las Conexiones Persistentes es reducir el esfuerzo de reabrir conexiones con MySQL. Cuando se crea una conexión persistente, queda abierta incluso después de que el script haya acabado de ejecutarse. Dado que Apache reutiliza sus procesos hijos, el siguiente script reutilizaría la misma conexión MySQL.
En la teoría suena muy bien. Pero desde mi experiencia personal (y la de muchos otros), esta característica acaba por no merecer la pena. Puedes tener serios problemas con los límites de conexión, problemas de memoria y mucho más.
Apache ejecuta de forma extremadamente paralela, y crea muchos procesos hijo. Esta es la principal razón por la que las conexiones persistentes no funcionan muy bien en este entorno. Antes de que consideres usar la función mysql_pconnect(), consulta a tu administrador de sistemas.
Buscar en un campo separado por comas en MySQL
Debido a un desarrollo en el que actualmente trabajo, me tope con esto que resulto ser muy sencillo de hacer, pero no esta tan documentado como se espera. Que pasa si tienes un campo con cadenas de texto o enteros separados por coma, como categorías, nombres etc.
Un ejemplo practico seria, el campo “cats” tiene un contenido como ’2,11,10,1,16′, si usamos el tradicional LIKE:
SELECT * FROM tabla WHERE cats LIKE '1';